
Hey data fans! Are you fascinated by data? Do you love digging into databases and spreadsheets to uncover insights? Then you’ll enjoy this beginner’s guide to understanding databases and how they evolved.
Let’s start from the beginning!
Data storage has come a long way since the days of manual thread patterns in looms. The evolution of storage devices has been driven by the increasing need for faster, more reliable, and higher capacity data storage. Let’s take a trip down memory lane and explore the fascinating history of data storage, from punch cards to the futuristic possibilities of DNA.
Basile Bouchon and the Birth of Data Storage:
In 1725, Basile Bouchon invented a method to store patterns of thread in a loom using a length of paper tape punctured with holes. This marked the beginning of data storage, as these punched paper tapes allowed for the automation of loom patterns, replacing manual labor.

The Rise of the Jacquard Loom:
Over the years, Bouchon’s invention continued to improve, culminating in the creation of the Jacquard loom in 1805. This revolutionary machine utilized punched cards to control its operations, paving the way for further advancements in data storage.

Herman Hollerith and the Pioneering Punched Card:
In 1884, Herman Hollerith received the first patent for a data storage device – a punched card system. Working at the U.S. Census Office, Hollerith’s invention greatly expedited the census process, reducing the time required from eight years to just one.
The Birth of IBM and the Magnetic Tape Era:
Hollerith went on to establish the Tabulating Machine Company in 1896, which later merged with other companies to form IBM. Magnetic tape emerged in the 1950s as a replacement for punch cards, offering higher storage capacity and durability. This technology revolutionized data storage and became a mainstay in computer systems for several decades.

The Internet Age and the Need for Massive Storage:
The rise of online shopping and social media platforms like Friendster, MySpace, and Facebook created an explosion of data. Storage technology rapidly evolved to meet this demand, with magnetic disk drives and optical devices like CDs and DVDs leading the way.
The Advent of Solid-State Storage and Optical Storage:
As computers became more commonplace in the 1960s, 1970s, and 1980s, the cost of magnetic storage and computers drastically declined. However, solid-state storage devices (SSDs), such as flash drives, began to gain popularity due to their reliability, smaller size, and lower power consumption.
The Future with DNA Storage:
Now, scientists are exploring DNA storage. Synthetic DNA molecules are being utilized to store data using the four-character DNA code, providing the potential for long-term data preservation and incredible storage capacity. DNA storage could potentially last for millions of years and allow for exabyte-scale data storage in devices as small as a grain of sand[1].
The history of data storage is full of remarkable milestones, from the humble punch cards to the revolutionary DNA-based storage. As technology continues to advance, it will be exciting to witness how data storage evolves and what the future holds for our increasingly data-driven world.
The Problem with Plain Old Files
See, data hasn’t always been neatly organized in tables and databases. everything used to be stored in basic file systems. Can you imagine? Just files of data strewn everywhere, no consistency or structure. It was like my closet on laundry day – a complete mess!
These file systems worked okay at first when data needs were simpler. But as companies required more complex data storage, the flaws in this approach became as obvious as that mustard stain on my favorite white shirt. 😿
File systems made it tough to integrate data. For example, an employee file might contain payroll info while their benefits data was in another file. To get a full picture, someone would have to dig through multiple files. Not very efficient!
Another issue was data redundancy. With information copied in multiple files, it was easy for inconsistencies to creep in. Think about having the same phone number stored in 5 different spreadsheets and directories. Yikes! If I needed to update my number, I’d have to change it in all those places. No thanks!
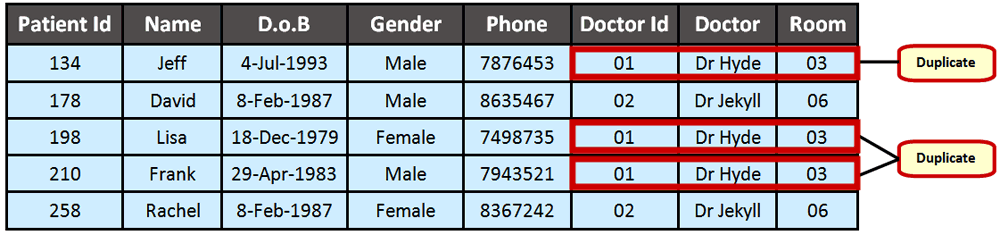
These file systems also lacked ways to maintain data integrity, security and prevent data corruption. It was like storing important documents in a leaky old cardboard box instead of a safe locking drawer.
Hello Database Management Systems! 👋
To address these problems, clever computer scientists developed database management systems (DBMS). This specialized software organized data storage in smarter ways, like:
- Hierarchical databases: Data organized in a tree-like structure. Worked okay but made changes complex.
- Network databases: Stored data with more flexible relationships. Still not ideal.
- Relational databases: Stored data in tables with defined relationships. Bingo!
Relational Databases For the Win!
Relational databases organize data into tables, which makes it much easier to connect related data points. For example, an employees table stores employee details while a benefits table stores their benefits info. The defined relationship between the two makes accessing a full employee profile simple.
Unlike messy file systems, relational databases reduce redundancy and improve integrity through features like:
- Primary keys that uniquely identify each row
- Constraints that validate data (e.g. dates must be in correct format)
- Access controls that prevent unauthorized access
This structured storage in relational databases works great for typical business data like names, addresses, order details etc. That’s why they still dominate business applications today.
New Data, New Databases
In our digital era, data comes in all shapes and sizes – emails, social posts, photos, videos, sensor readings. This unstructured data doesn’t fit neatly into relational database tables.
That led to the rise of NoSQL “non-relational” databases like MongoDB that can handle messy, massive datasets. Relational DBs scale up by using bigger servers, while NoSQL scales out across many smaller, inexpensive servers.
Big Data for Big Ambitions
Speaking of massive datasets, let’s talk big data! As you can imagine, storing and analyzing petabytes of social media posts or website analytics requires serious computing power.
That’s where big data management systems come in. They make it possible to gain insights from mountains of data, whether it’s improving healthcare outcomes, optimizing supply chains or predicting customer needs.
Let’s Not Forget Data Warehouses!
Data warehouses play a pivotal role too. Whereas relational databases optimize for transactions, data warehouses store huge amounts of historical data. Companies summarize transactional data from relational databases to identify long-term trends and patterns.
Data warehouses integrate internal business data with external industry data, providing a “single source of truth” for strategic business analytics and reporting.
Turning Data into Information Gold
Databases give us the power to store and organize data – but it takes humans to turn data into meaningful insights! We contextualize and interpret organized data to create valuable information that drives smart decisions.
So in summary, database management systems evolved to meet growing data needs. Relational databases make structured business data easy to store, access and analyze. And complementary solutions like data warehouses and NoSQL databases opened the doors to bigger data ambitions.
But don’t forget the human element! To gain the full value from data, we need curious minds to ask questions and uncover the stories hidden within the data.
So are you ready to embark on an exciting career in data? With the right database skills and the ability to discover meaning in data, you’ll be a superstar in any data-driven field from business analytics to scientific research and beyond! Subscribe to my newsletter for more insights into database management!
Resources
- Link – New York Times Article on DNA Storage
- Database Management Textbook


Leave a comment